Glossary
SnapAttack introduces several new concepts, some of which may be overwhelming at first. This glossary aims to explain some of the more nuanced details of the platform, and dive deeper into how they work and affect what you see from page to page.
Content Types
Currently SnapAttack has three main types of content — intelligence, threats, and detections.
 Intelligence
Intelligence
Intelligence is information about a specific threat, actor or campaign. In SnapAttack, we adopt a broad view of intelligence to include a variety of public and private sources. Public sources can be more informal, to include articles, blog posts, or Twitter tweets. Private sources can include commercial threat feeds or intelligence created by an internal CTI team.
 Threats
Threats
Threats are a way for red teams to memorialize adversary tradecraft. SnapAttack captures lots of data about threats, such as event logs, keystrokes, and a screen recording of activity. It's meant to make sharing knowledge of adversary behaviors easy, without having to constantly repeat the process.
Trivia
The name "SnapAttack" came from our initial prototype. We knew we wanted to create the best behavioral detections, but in order to do that we first needed to know what "bad" looked like. So we set out to create a repository of known attacks, and find a way to "snapshot" them.
 Detections
Detections
Detections are a way for blue teams to identify and alert on adversary tradecraft. SnapAttack makes it easy to add rigor to the detection development lifecycle (DDLC) — including capturing ideas and tracking a detection backlog, creating detections with our advanced detection builder, tuning and testing to ensure it hits on true positives while minimizing false positives, tracking and managing deployments, and continuously improving and maintaining your detection library.
Subscription Content
SnapAttack has an ever growing collection of content that is available to subscribers, contributed by both the SnapAttack team as well as other customers and the community. Full platform subscribers will always have access to all available public and shared content. Contact us to schedule a demo or setup a POC for your organization.
Threat Actors
A threat actor is any person or organization that intentionally causes harm to a computer system or network. Generally, higher profile threat actors (e.g., nation states, criminal organizations) are given names and their campaigns and activities are tracked across intelligence reports. This is often more of an art than a science. Some threat actors have multiple names associated with similar activities due to various organizations tracking similar activities by different names. Threat actors may also partially overlap with other actors, and some organizations may disagree on specific actor activity. We source threat actors from the MITRE ATT&CK framework, and do our best to track overlaps between actor groups and aliases (e.g., APT34 tracked as Helix Kitten, OilRig, etc).
Detection Confidence
Detection confidence is calculated based on the number of expected or actual hits the detection will have in your environment over a 7 day period. It gives some level of understanding of the ratio of true positives to false positives, and how much manual effort may be needed to review the detection hits. Confidence should not be confused with severity; you could have a low confidence that something has a high severity (e.g., credential dumping) or a high confidence that something is not that severe (e.g., adware).
Highest
Highest confidence detections will have 0-1 hits over a 7 day period. These are considered IOCs and have no expected false positives. They are not expected to hit, but when they do, you should take immediate action.
When highest confidence detections have not been validated against a true positive, you should be careful to ensure that the logic and syntax are correct as these may be problems that would cause them to never hit in the real world.

High
High confidence detections will have 2-50 hits over a 7 day period. These are very narrow behavioral detections, and should have very low false positives. They are suitable for triage by a Tier 1 / Tier 2 SOC analyst.

Medium
Medium confidence detections will have 51-500 hits over a 7 day period. These are considered behavioral detections and will have some expected false positives. They can be investigated manually or used as part of a hunt plan.

Low
Low confidence detections will have 501-5000 hits over a 7 day period. These are considered behavioral detections but will have many false positives. They are suitable for correlations and threat hunting, or should be tuned to improve the confidence score.

Lowest
Lowest confidence detections will have over 5000 hits over a 7 day period. These are considered haystacks, with a majority of hits being false positives. They are suitable for correlations and threat hunting, but would not be manually reviewed.

Unknown
Unknown confidence detections are new to the platform and their confidence has not yet been calculated, or we don't have enough real-world data to accurately calculate a confidence score. Confidence scores are calculated during the testing and publishing phases for newly created detections.

Visibility
All content types in the system have a visibility state.
Draft
Drafts are the default state for all new content. If you save content without explicitly selecting publish, it will be saved in the draft state. Draft content is only visible to the author, so other users in the platform will not see your drafts.
Draft content items have a gold badge on the search and the content pages. They do not show up in search results by default.

Published
Published content is live and viewable to users in the platform. As it is the primary visibility state, published content does not include a badge.
When a new captured threat is published, all existing detections are run against the event logs from that threat. Detection hits will populate on the timeline for the threat over the next few minutes (we call this process backfilling). As new detections are added to platform, they are run against all existing threats.
When an new detection is published, it is run against all existing threats in the platform. Depending on the detection complexity and performance, this can take a few seconds to a few minutes to run, though in rare cases may take longer. Published detections will also be run against new threats as they are added to the platform.
Workflow States
Detections have a separate workflow state field to track their progress trough the detection development lifecycle (DDLC). The development, testing, verified, and rejected workflow states can be used for your convenience. Any one of these states can be set by "state" dropdown on the detection page.
Deployed
The deployed state is special. It is meant for tracking detections that have either been manually deployed to a production environment, or automatically deployed through a configured integration. On the detection page, a user can click on the "deploy" button to deploy the detection. A user can also click this button to undeploy a detection.
If integrations are configured and enabled, the user may select a product to deploy the detection to (e.g., EDR, SIEM, etc.) and SnapAttack will automatically deploy that detection.
Deployed detections have a green badge on the search and detection pages.

Validation Criteria
There are three ways that detection hits can be validated against a labeled attack. All of these matches are time-bound to +/- 5 seconds, so if an attack label is off it could result in an incorrect validation.
1) By MITRE ATT&CK tags.
Attacks and detections should both have labeled ATT&CK tags. The platform compares them at technique and sub-techniques levels. Using the example T1059 Command and Scripting Interpreter, if an attack and detection both have the same technique tag (T1059) and fall within the time window, the detection will be counted as validated. If an attack or detection were tagged with T1059 and the other was tagged with a more specific sub-technique (e.g., T1059.001 PowerShell) and still fell within the time window, the detection would be counted as validated. Two different sub-techniques from the same parent technique (e.g., T1059.001 PowerShell and T1059.006 Python) will not validate, so it is wise to choose the most descriptive and appropriate ATT&CK tag when possible.
2) By event log.
When an attack label has been added from Splunk or the process graph, it has a specific event log attached to it. If that specific event log were to match on both a labeled attack and detection, the detection will be counted as validated. This gives some additional leeway for when ATT&CK tags don't match. For example, if a red teamer labeled an attack as T1546.003 WMI Event Subscriptions for persistence, but a detection that detected it is tagged with T1047 Windows Management Instrumentation for execution, the detection will be counted as validated because they reference the same event log.
3) By process.
When an attack label has been added from Splunk or the process graph, it has a specific event log attached to it. If the Process ID (PID) or Process GUID from the labeled attack matches the PID or Process GUID from a detection hit, and the two events fall within the time window, the detection will be counted as validated. This gives some additional leeway to detections. For example, a red teamer labels the process creation event for modifying a registry key with reg.exe, but a blue teamer's detection hits on a registry modification event that was triggered by that same process, the two will be validated even though they do not share the same event log.
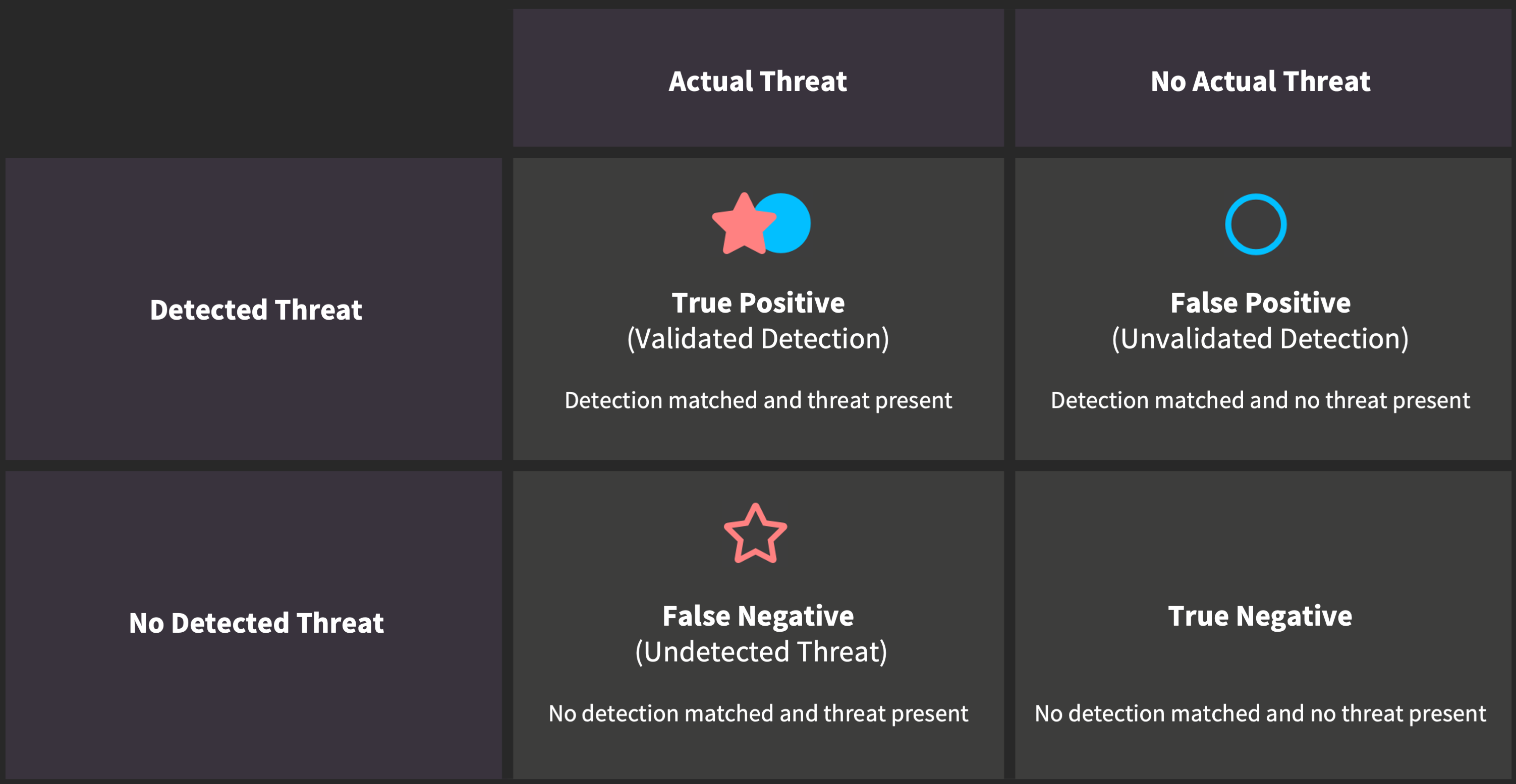
Validation Status
We track the relationship between labeled attacks ( red stars) and detection hits (
red stars) and detection hits ( blue circles) as validation status.
blue circles) as validation status.
For those with a data science background, you might understand these terms best in the context of a confusion matrix. Our detections are the predictor of malicious activity, and the captured threats are our actual data of malicious activity.
Did you know?
The badges you see on a detection are the highest validation the detection has achieved. If a detection has ever been validated, it shows as a validated detection, even if it hits on threats where attacks haven't been labeled. Similarly, an unvalidated detection has never hit near a labeled attack, and may be highly false positive.
 Validated Detection
Validated Detection
Validated detections are true positive detection results. When a detection hit ( blue circle) matches a labeled attack ( red star), the icons are filled in to denote that the detection gaps are closed.
The ultimate goal is to create validated detections, which confirm our hypothesis that an event is a malicious indicator by testing it against a known threat. Validated detections are true positives. The detection confidence measures the ratio of true positive hits to false positive hits. A highest confidence detection should only have true positive hits — an example of which may be an indicator of compromise (IOC) — whereas a low ranked detection will have many false positives but is appropriate for creating haystacks for threat hunting.
 Detection Gap
Detection Gap
Detection gaps are likely false positive detection results that need additional review. When a detection hit ( blue circle) has a nearby labeled attack (
blue circle) has a nearby labeled attack ( red star), but they don't match on any validation criteria, the icons are left hollow to denote that a detection gap exists.
red star), but they don't match on any validation criteria, the icons are left hollow to denote that a detection gap exists.
Detection gaps are existing detections that need improvement. When a labeled attack ( red star) and a detection hit ( blue circle) are in close proximity, but they have mis-matched MITRE ATT&CK mappings or processes, the icons are left hollow to denote that there is a detection gap. These can be improved by reviewing and updating existing detections or adding additional attack labels.
Unvalidated Detection
Unvalidated detections are false positive detection results. When a detection hit ( blue circle) has never had a labeled attack ( red star) in close proximity, the blue circle appears hollow. These can be improved by executing and capturing a threat that would trigger the detection.
 Untested Detection
Untested Detection
Untested detections are the red team's backlog. These are detections that have never triggered on a threat in our threat library. These can be improved by executing and capturing a threat that will trigger the detection.
Undetected Threat
Undetected threats are seen in the platform as hollow red stars. When the threat is detected by a detection, it is seen as a solid red star.
A user can label an attack on a captured threat by adding a red star. If the labeled the attack ( red star) does not have a matching detection hit ( blue circle), it is categorized as an undetected threat.
Undetected threats are the blue team's backlog. These can be improved by reviewing the log data from the captured threat and creating a new detection.